大赛常规 Q&A
Q1: 贵司在算法一中F-OFDM中提到可以使用Matlab仿真,在上交材料时提供Matlab源码。但在赛事章程中材料提交只要求C/C++。想确认这个以哪个为准,即初赛材料提交是否可以是Matlab源码。
A: 可以使用Matlab仿真,提交Matlab源码。
Q2: SCMA题目前面的Turbo模块硬件我们也要实现吗?
A: FPGA上Altera会提供CRC,Turbo,FFT/IFFT的IP核供参赛队调用,请关注FPGA板块提供的材料链接。
Q3: 2015亚洲创新设计大赛 - 5G专题竞赛是什么样的比赛?
A: 2015亚洲创新设计大赛 - 5G专题竞赛是提供亚太及全球学生及教师一个 FPGA 作品设计观摩、竞赛的交流平台。今年特辟5G专题竞赛,则是让参赛学生能利用更为前瞻的技术,激发更为尖端的创意呈现,并希望在提供学生无限的作品发挥空间下,提升其 FPGA 设计的兴趣及技巧,让其创新与创造力尽情发挥和完全实现。
Q4: 比赛的奖项有哪些?
A: 更多详情,请见奖项介绍
Q5: 如何报名参加比赛?
- 主办单位由 2015 年 05 月 11 日起至 2015 年 06 月 11 日止接受线上报名,请完整填写所需资讯。
- 报名成功者将收到系统发出的确认信、参赛队伍 ID 号码以及一组账号密码。
- 参赛者可利用账号密码登录大赛网站,来提交创新大赛文稿
Q: 比赛项目有哪些?
A: 更多详情,请见大赛赛题
Q: 需要符合什么资格才可以参加比赛?
- 全国所有大专院校电子、通信、计算机及相关专业研究生、博士生、高年级本科生均可报名。
- 每位学生限参加一组队伍,每组队伍不超过 3 名学生,可以由一位学校老师指导或者学生独立组队。
F-OFDM Q&A
Q1: 信道要求是LTE的ETU3km/h和EPA3km/h与AWGN信道。那么前边的OFDM符号生成是不是也要根据LTE的协议来生成呢?因为LTE的信道是有协议的嘛。还是说不管信道是什么,OFDM symbol的生成是独立生成的?
A: OFDM symbol生成跟信道无关。
Q2: 同步信号和导频结构都是自己设计?
A: 同步和导频结构可以按照LTE设计。
Q3: 是按照LTE的标准生成的数据帧格式吗?
A: 数据帧结构请参考LTE FDD下行帧结构,具体参数配置在胶片P22上有。
- 子带一的帧结构可全完按照LTE FDD下行帧结构设计,但只需考虑数据信道和导频,无需考虑其他控制信道;
- 子带二是非LTE标准的,大家可以参考子带一的帧结构进行频域上的缩放,以及时域上的切片即可。
- 总体上,除了P22要求的参数之外,其他帧结构相关参数请大家自由设计,不做具体要求。
Q4: 两个子带的基本链路参数如下表所述的表格中有一项为 Guard tone number: 0/1/2/3,这个参数是指什么?
A: 在f-OFDM框架下,两个子带采用了不同的参数,它们并不是正交的,虽然我们采用了滤波器去限制各个子带的带外泄露,但仍不能完全保证子带之间无干扰。因此,需要考虑在两个子带之间空置保护子载波,所谓的“Guard tone”就是保护子载波的意思,0/1/2/3分别代表了保护子载波的数量。请大家在仿真和实现中多尝试一下不同保护子载波数量所带来的性能变化。
Q5: 按照LTE标准来做Resource block的话,那需要考虑 BCH, PSS, SSS and PDCCH这些东西吗?还是只需要考虑信息和CSR?如果考虑的话那根据子带2的参数配置如何去设置它的Resource block,3GPP TS 36.211标准里暂时没看到看到那样的配置,还是其他协议里有?
A: 不需要考虑任何控制信道,只需要考虑PDSCH以及CRS导频即可。LTE协议没有提供30KHz子载波间隔的RB定义和CRS图案,大家可以参考15KHz的定义方式,进行缩放和切片即可,如果有精力的话,也非常欢迎大家自行设计更加合理的导频图案以及RB定义。
Q6: 复赛要求用FPGA实现,请问下信道模型也要用FPGA实现么?
A: 是的,但是信道实现比较复杂,我们可以用简单的等效方法来实现。目前暂定由我们提供一组信道冲击响应的数据,大家只需要把这组数据读到FPGA中,用冲击响应对信号进行滤波即可。具体的信道冲击响应数据待后续提供。
Q7: 在子载波映射的时候,第二个子带数据的中心频点已经不是零了,这个时候是还按第一个子带的方式映射上去再搬移到第二个子带的中心频点上(按照基带上变频的方式变到第二个中心频点上),还是说在映射的时候已经可以直接映射到第二个频带上,如果是直接映射到第二个频带上怎么操作呢?
A: 两种方法都是可以的,我建议你可以从实现复杂度的角度去评估一下哪种方法更好。第二种方法的话,可以参考我们提供的f-OFDM算法说明文档,里面给出了一个例子。
Q8: 根据赛题规定的要求计算出48个子载波,我想问一下是以符号进行编码调制,还是以资源块呢,若以符号进行编解码,假设采用QPSK,turbo 1/3, CRC24 (不考虑导频) 则传输的有效bir=48*2/3-24=8, 会不会太少了?
A: 以资源块为粒度进行编码,48个子载波对应的资源总数应该是48*14=672个,而不是48个。
Q9: 通过文献里的参数计算,子带1中有48个子载波,FFT_size为2048,那么肯定要过采样,但2048/48不是整数倍,这时怎么过采样呢?
A: 48个子载波指的是有效数据子载波,其他2048-48 = 2000个子载波上都是映射0。因此不需要特别的过采样操作,IFFT变换本身也就是完成了过采样。
Q10:在官网的文档里面有下面的一句话:
以两个子带均为720KHz带宽为例,则M1=48,M2=24。假设子带1的子载波映射编号为[-24, -1] [1 24], 中间的0号子载波为直流分量,不做数据映射。假设N1=0,N2=1,则子带2的子载波编号为 [14, 37]。我的疑问是:子带1已经编了[1 24],子带2的编号范围[14 37]是不是和子带1的重合了,应不应该是[25 48]呢?
A: 子载波的编号和子载波所映射的频率位置是有严格对应关系的。一个简单的方法是,用子载波间隔乘以子载波编号,看看两个子带是否有重复的,如果两个子带有重叠的部分,则说明设置的不够合理。
Q11:按照LTE的参数写的链路,而OFDM的频谱带外性能意外地有点好,带外衰减达到-70多dB,而我看很多论文根本衰减不到这么多,想不出原因所在。而滤波后的数据过衰落信道(EPA)后,感觉由于滤去了一些有用信息,反而造成了误码,从而造成OFDM的系统性能反而比FOFDM的性能好,求问有没有能解决的办法?
A: 看起来功率谱是过于好了,通常OFDM的带外衰减会在-30多dB的时候开始出现平台。请确认一下画功率谱的方法是否合理?建议可以用matlab自带的函数或系统对象画功率谱。另外,关于F-OFDM性能损失的原因,请确认一下滤波器的具体配置,是不是滤波器设计的不够合理,比如说带内失真或者时域严重ISI导致的性能损失?
Q12:系统的CRC需要按照LTE标准两次编码么,它的纠错方法是什么?
A: CRC的主要目的是检错,大家最好按照LTE的方式做,如果传输块(LTE术语:Transport Block, 缩写TB)太大,则最好把TB切割成更小的Code Block(CB),以免过高的编码和译码复杂度,具体实现方式和参数取值请参考LTE协议。CB和TB都可以加CRC,CB加CRC的目的是当任意一个CB的CRC校验未通过时,就可以停止整个TB的译码,反馈NACK。当所有CB的CRC校验都通过之后应当再用TB的CRC进行校验,进一步避免校验错误。
在本次比赛所要求的范围内,因为TB较小,还不涉及TB分割成CB的问题,所以不强制要求实现这个功能。但如果有精力做了这部分内容,那是可以加分的项目。
之于你说的CRC的纠错方式,我没理解你的意思,请补充细节。
Q13:根据参考资料里面给的:
F2=(24+0)*15khz+(12+1+0.5)*30khz=765khz
这里的为什么要加0.5,在仿真的时候,若中心频点设置为765khz,出来的频谱很差,带外衰减也很差,若中心频率计算时不加0.5,则带外衰减会正常。
A: 是这样的,因为子带2的总子载波数量是偶数,那么子带2的中心频点不可能落在其中一个子载波所在的频率上,而应该在中心的两个子载波的中间。例如:子带2共有24个子载波,那么显然其中心频点的位置应该在第12个和第13个子载波的中间,这是为什么(12+0.5)出现在公式中的原因。
Q14:标准的LTE子载波间隔是15kHz,一个TTI包括14个symbol,也就是7+7。
现在的是30kHz配置,根据大赛官网PDF上的配置,一个TTI包括5个symbol.
那么F-OFDM的一个TTI,采用12个symbol 可以吗?就是前面7个是标准的15kHz的symbol,后面的5个symbol是30kHz的?然后分别对7个和5个进行加窗处理,抑制OOB。
A: 请再仔细阅读一下培训材料,你没有准确理解F-OFDM的意义,两个子带在频率上是相邻的,在时间上是同时存在的,所以不存在你说的前7个用子带1,后5个用子带2参数的问题。
Q15:AWGN信道 插入删除pilot 会对BLER有影响么(pilot代码正确)
A: 基本不会有影响。唯一的一点是由于pilot的插入导致有用资源减少,会导致码长变短,除非插入的pilot非常多,否则对码长的影响也是很微弱的。
Q16:我问下 子带不是48或24个载波么,映射完后进行2048点IFFT时要补很多0么
A: 是的,要补够2048或者1024点IFFT
Q17:子带2不是LTE标准,那它一个帧里包含多少TTI啊
A: 在本次比赛中,我们没有定义帧的概念,只有TTI的概念,所谓TTI和LTE中的subframe的概念类似,子带2的一个TTI包含5个OFDM符号。由于不影响实现,我们不需要进行帧的定义。
Q18:赛题里要求的1/3,1/2和3/4的Turbo码率具体是怎么计算的?它和Turbo码母码码率是什么关系?是否采用LTE的速率匹配机制?
A: Turbo编码原则上采用LTE的机制,详细的方法描述请参考3gpp TS36.212文档。这里主要对大家比较关心的如何确定TB size(TB表示transport block,即编码前的比特数量),如何实现赛题要求的码率进行举例说明。
- 首先计算子带内的总资源数量。以子带1为例,720KHz的子带带宽上总共包含48个子载波,并且每个TTI包含14个OFDM符号,因此子带1总的资源数量为48*14=672个.
- 然后扣除导频开销。假设采用LTE中的CRS导频图案,则在720KHz的子带带宽上共有32个导频符号,因此剩余的有效资源数量为672-32=640个。(注意:如果实现了同步信道、控制信道等,也应扣除这些物理信道的开销)。
- 计算编码后的总比特数。假设QPSK调制,每个调制符号包含两个比特的信息,则编码后的总比特数为640*2=1280个。
- 计算TB Size(编码前的比特数量)。假设要求的码率为1/2,CRC长度为24,则TB size为 (1280)*1/2 – 24 = 616。(注意:如果TB size超过6144,需要切割成CB进行多次Turbo编码,每个CB都需要加CRC)。
- 生成长度为TB size的随机比特。在本例中,应生成616个随机比特。
- 加CRC并进行turbo码编码。LTE中的Turbo码母码(所谓母码码率,指的是在进行速率匹配之前的码率)码率为1/3,则编码后的比特数量为(616+24)*3 = 1920
- 速率匹配(打孔)。请按照LTE 36.212中给出的rate matching方法进行打孔,使rate matching后的比特数量为1280个。
SCMA Q&A
Q1: 请教,如何能将SCMA中每个发送出去的码字的能量均归一化到1呢?
A: 你可以直接把码本scale一下,得到归一化功率的码字。
Q2: SCMA题目前面的Turbo模块硬件我们也要实现吗?
A: 会提供IP核,请关注FPGA板块。
Q3: 我想请问一下,用在大赛官网给的PDF文件里给出的码本,专家们在高斯信道下的仿真结果性能如何,我做的在信噪比为8db左右时误码率才接近0,与论文“SCMA Codebook Design”里给的在高斯信道下的仿真结果相差很远。谢谢!
A: 建议注意一下SNR的定义,是否归一化功率,以及码率等问题。
Q4: 请问SCMA码字发送分时候需要将码字的实部与虚部分开,经交织后发送出去吗?还是直接发送复数码字出去?
A: 我们是直接发送,没有做这部分交织。之前有试过效果有限。
Q5: 如果采用PPT给定的参数指标,是否可以跳过码本设计阶段而直接使用PPT中的参考码本,把主要精力放在译码算法上?
A: 材料中给出了码本供大家使用,该码本是经过一定优化方法得到的。大家可以跳过码本设计的阶段,把主要精力放在译码算法上。如果您在码本设计上有突出贡献的另议。
Q6: 我想请问一下论文中仿真的BLER中的block的大小是怎么定义的,即一个block包含多少比特,谢谢!
A: 你好,一个原始block可以设置为包含1000个比特。大赛PPT后面参数建议有写。
Q7: 在SCMA.ppt第11页中,经过N次迭代后,在VN节点对码字m的猜测Qv(m),m=1,2,3,4,有以下几个问题:
(1)是否是找出最大的Qv(m),然后就可以判断每个数据层的码字,例如Qv(2)最大,则判为01;
(2)v=1,2,...,6.可以判决出6个2bit码字,这样的理解对吗?
(3)计算对数似然比时,LLR=log(P(b=0)/P(b=1)),在下面的推导中求和符号m:b(m,x)是什么意思呢?最后输出6个对数似然比吗?
A: 1. 并不是直接判断码字是什么,而是用它来求比特LLR。比如Qv(2)最大,我们当然可以认为它最可能是01,但是其他码字也要一起算上,来计算没一位的LLR。
2. 对。
3. b(m,x)是表示码字m中的第x个比特的意思。例如此时我们每个VN都有2位比特。这个公式LLRx是求第x个比特的LLR的意思。
Q8: 请问本次大赛,要求的误码率是加上turbo编码以后的还是没加以前的,误码率最小应该是多少?还有,例如用户信息1200bit,turbo编码输出应该是2400bit还是4800bit?
A: 加上Turbo以后的。误码率要求小于0.001。我们后面也定了信道编码码率为1/2, 用户原始信息长是1000bit,所以Turbo编码后应该是2000bit。
Q9: 请教,如何能将SCMA中每个发送出去的码字的能量均归一化到1呢?
A: 你可以直接把码本scale一下,得到归一化功率的码字。
Q10: SCMA题目前面的Turbo模块硬件我们也要实现吗?
A: 会提供IP核,请关注FPGA板块。
Q11: 我想请问一下,用在大赛官网给的PDF文件里给出的码本,专家们在高斯信道下的仿真结果性能如何,我做的在信噪比为8db左右时误码率才接近0,与论文“SCMA Codebook Design”里给的在高斯信道下的仿真结果相差很远。谢谢!
A: 建议注意一下SNR的定义,是否归一化功率,以及码率等问题。
Q12: 请问SCMA码字发送分时候需要将码字的实部与虚部分开,经交织后发送出去吗?还是直接发送复数码字出去?
A: 我们是直接发送,没有做这部交织。之前有试过效果有限。
Q13: 如果采用PPT给定的参数指标,是否可以跳过码本设计阶段而直接使用PPT中的参考码本,把主要精力放在译码算法上?
A: 材料中给出了码本供大家使用,该码本是经过一定优化方法得到的。大家可以跳过码本设计的阶段,把主要精力放在译码算法上。如果您在码本设计上有突出贡献的另议。
Q14: 我想请问一下论文中仿真的BLER中的block的大小是怎么定义的,即一个block包含多少比特,谢谢!
A: 你好,一个原始block可以设置为包含1000个比特。大赛PPT后面参数建议有写。
Q15: 在SCMA.ppt第11页中,经过N次迭代后,在VN节点对码字m的猜测Qv(m),m=1,2,3,4,有以下几个问题:
(1)是否是找出最大的Qv(m),然后就可以判断每个数据层的码字,例如Qv(2)最大,则判为01;
(2)v=1,2,...,6.可以判决出6个2bit码字,这样的理解对吗?
(3)计算对数似然比时,LLR=log(P(b=0)/P(b=1)),在下面的推导中求和符号m:b(m,x)是什么意思呢?最后输出6个对数似然比吗?
A: 1. 并不是直接判断码字是什么,而是用它来求比特LLR。比如Qv(2)最大,我们当然可以认为它最可能是01,但是其他码字也要一起算上,来计算没一位的LLR。
2. 对。
3. b(m,x)是表示码字m中的第x个比特的意思。例如此时我们每个VN都有2位比特。这个公式LLRx是求第x个比特的LLR的意思。
Q16: 请问本次大赛,要求的误码率是加上turbo编码以后的还是没加以前的,误码率最小应该是多少?还有,例如用户信息1200bit,turbo编码输出应该是2400bit还是4800bit?
A: 加上Turbo以后的。误码率要求小于0.001。我们后面也定了信道编码码率为1/2, 用户原始信息长是1000bit,所以Turbo编码后应该是2000bit。
Q17: 求问一下各位,大家实现出来max-log MPA与log MPA相比,性能大概损失多少呢?
A: 我们有仿出,大概相差0.3dB
Q18: 在step2 FN update的地方, exponential operation over f_n function需要乘上 I_v2->g和 I_v3->g, 那化简时能忽略常数项吗?
A: 这些项本来是相乘,但在log域的话,就是加了。你相加处理就OK
Q19: 请问信息比特1000是每个用户1000还是六个用户一起1000?
A: 每个用户分别1000。
Q20: 请问答疑时候ppt中,那个outer loop可以提高性能的图中,constellation probability calculator是用LLR来改变MPA decoder的输入先验概率吗?
A: 是的,从Turbo decoder反馈过来的外验来作为MPA decoder的先验。
Polar Code Q&A
Q1: 是按照大赛要求直接按给出的算法进行编程实现,还是在给出算法基础上设计新算法,再编程实现呢?
A: 实现给出的算法即可,甚至参数都可以选择最简单的去实现,比如硬件实现时选择短码(码长256),且List大小选择1(相当于SC译码)。但如果想获得更好的名次,还是要尽可能去实现一些更有挑战性的参数。
至于算法创新,如果能够提出更好的新算法,当然会有非常高的加分。只是要注意算法的实现复杂度哦。相比算法,建议可以更多地考虑在实现方面做一些创新尝试,比如硬件结构、量化等。这一类创新设计在实现时风险较低,且往往可以达到很显著的效果。
Q2: 似然值L1、L2再次递归时,u怎么变换?
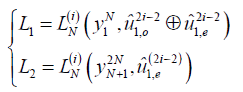
A: 再次递归时,依然使用这两个公式。若想更直观一些,可以将这里两个公式中“序列y的前一半或者后一半”以及“u序列的运算结果”用其它符号重新写一下。写成 LN(i)(z[1..N], v[1...N])的形式。之后继续使用这两个公式进行计算。
对于其中的模二加符号,材料里面没有特别说明这里的加法是bit-wise,也就是将两个序列对应位置的比特相加。 之后得到一个新的序列,可以记作v,它的作用相当于原来的u,然后继续递归。
Q3: 仿真程序处理速度有多快?
A: 参考一组仿真数据:在PC上用C写的软件仿真译码,L=32的时候译每一码块不到20ms(只统计译码,没有开任何降复杂度的算法开关,仿真PC是3G主频、4G内存)。如果用SSE/AVX优化的话,估计可以在10ms以内。N=1024 L=4时,平均每个码块译码时间约2.47ms。
不过,本次比赛主要是看FPGA实现,仿真代码只要性能优秀即可。
Q4: 生成矩阵FN 1024*1024 太大了,怎么存的? 路径复杂度相对FN 来说太小了
A: 如果是仿真的话,不管是Matlab还是C语言,都应该可以直接存下这个矩阵的。
其实,不需要去存储那个矩阵的,材料里面已经给出了等价于生成矩阵的编译码结构。编码的话,只需要一个1024*1的向量及若干的辅助变量就足够了。具体请查看大赛给出的材料或者参考文献。
Q5: 在电脑仿真的时候,可以把仿真的数据通过MATLAB画出了性能曲线图。FPGA实现的话,以什么作为输出?
A: 大赛的作品提交时,可写一段PC上运行的APP对编译码前后的信元数据进行比较输出BER及BLER v.s Eb/No性能曲线。输出详见赛题要求。
前期可以把数据读出来再通过MATLAB画性能图。最终提交作品时,能够有个APP实时显示是最好的。备注:FPGA板是安插在PC的PCIE插槽上运行的,实时译码数据可以暂存在缓冲区。比赛的核心是算法实现及其性能,有个好的UI当然也是欢迎和添彩的。
Q6: 信噪比的值与噪声方差的关系?
A: 信噪比在本赛题中取值为每个信息比特的发送功率与噪声功率之比,其定义如下:
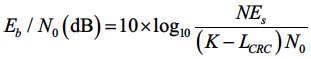
其中,ES=1,N0=2σ2。其中,噪声功率 N0 由噪声估计模块得到,在本赛题中,由于信道噪声是人为添加的,可以认为 N0 的正确值对译码器已知,即理想信道估计。