Profile - TW003
TW003
視覺作曲家
國立臺灣大學電機工程學系

Project
Name of Project: 視覺作曲家
Contest Advisor
Name: 簡韶逸
Members
No. Name 1 曾士豪 2 鄭為中 3 簡伯宇
Project Paper - view as Preliminary(2011/07/21), Final(2011/11/01), Draft, Latest
1. 設計介紹 (Preliminary Paper)
一、前言
音樂在人類文化的演進中扮演重要的角色,所謂「制禮作樂」正強調了音樂對人的影響。一首山歌,道盡彼端伊人的思慕;一曲小調,奏出過往時代的哀戚。紀錄這些音樂,就記錄了生活的喜怒哀樂。但一般人可能可以輕易哼出一段曲子,卻未必能夠用樂譜、樂器來紀錄與再現,樂理與演奏技巧阻礙了許多旋律的面世。
現在,藉由科技的力量,讓跨越一段段樂音而來的情感,在不同的時空,共鳴。二、從眼睛到耳朵
--作品介紹「視覺作曲家」的設計理念是「我手畫我曲」,與傳統音樂家藉由五線譜創作不同,直覺的彩色線條描繪,讓一般大眾都能輕鬆實現腦中跳躍的音符。只要在紙帶上對應的音高位置畫上線段,就會發出該音高的聲音。
設計靈感是源自於紙帶音樂盒,在紙帶上打點,透過音樂盒便可以發出聲音。進一步,我們不禁想問:「紙帶音樂盒的音色只有一種,是不是能夠利用這樣的架構,來實現多種樂器合奏呢?」為此,我們在紙帶音樂盒的架構基礎上,把打點改成了劃線,並加入顏色變化,透過不同顏色來表達不同的音色,使得使用上簡易許多,且創作能更加豐富多元。三、簡單,就是唯一的訴求
--操作方式「視覺作曲家」的本體是個精巧的音樂盒。將Token放到音樂盒上表示音色,在紙帶上繪製樂譜,捲動紙帶就可以發出編寫的音樂。
四、大家一起來
--應用領域與目標使用者「視覺作曲家」為音樂創作者開創全新的創作方式,把艱澀的混音工程、學習不同樂器的彈奏化為紙帶填寫。可以把它當作像是Reason等數位音樂製作軟體的替代,甚至是作為一種全新的樂器來使用。
本產品適合所有對音樂有興趣的人,特別是音樂創作者,不但操作方便,編曲時也不用擅長多種樂器或找不同樂手,只要使用視覺作曲家,便可以完成變化豐富的音樂,達成自己想像的編曲,小小的音樂盒讓樂曲創作的時間大大地縮短了。五、站在巨人的肩膀上
--以ALTERA設計的原因本產品之所以選用Altera的DE2系列產品的原因是因為Altera公司對於多媒體的套件做得十分完善,內建的Audio codec模組讓聲音可以簡單地透過音源線輸出、DE2系列產品可以簡單地和攝影機的模組做配合,龐大的logic element讓影像辨識的演算法和聲音處理的操作得以完成,除此之外,豐富的記憶體也是選用DE2系列的原因,不同種類的記憶體讓我們可以靈活的依照其特性運用在我們的設計當中。最重要的是,藉由這個多媒體平台,讓概念到實現變得簡單。(Revision: 3 / 2011-08-27 17:45:11)
2. 功能描述 (Final Project Paper)
一、實體外觀
圖2-1 實體外觀視覺作曲家的外型就像一個紙帶音樂盒一樣。將紙帶插入盒中,放上token,轉動把手,就會發出聲音。
二、紙帶的編寫方式
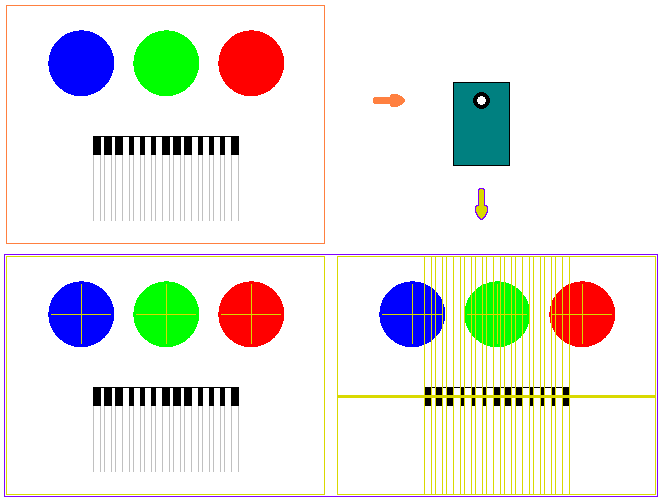
紙帶的範例如下圖
圖2-2 紙帶編寫範例紙帶的前端有一黑白相間區域,供系統掃描以辨識各列分界;中間直條的淺色線條是為了方便作曲時估算節拍的小節線,兩個小節線之間稱為一小節;淺色橫線是區分音高的界線。預設的音域最下面列是C4(中央C),往上依次是C#4、D4…到B5。最上面一列是指令列。在不同的列上依照節拍畫上顏色就可以發出該顏色的音色以及所在列的音高。而在指令列畫上不同的顏色組合就會有不同的效果(如升八度、降八度等等)。上圖是以巴哈的G調小步舞曲為例,在第一小節加上了紅色音色升八度的指令,所以雖然有些地方紅色和藍色畫在同一個區間內,但實際上藍色音是比紅色音低八度的。
圖2-3 紙帶外觀三、Token系統
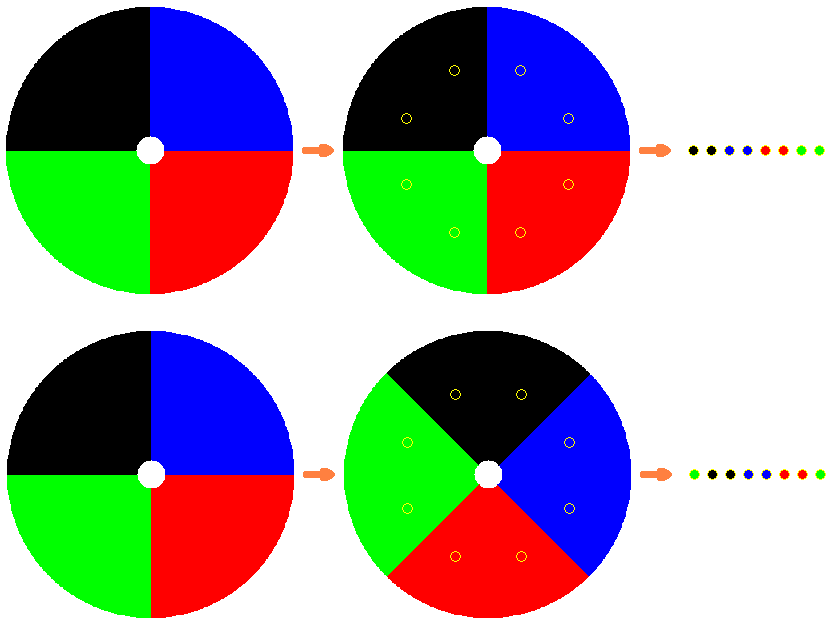
圖2-4 Token外觀Token是如圖2-4一樣的圓形指示物,上面分成四個區塊,每個區塊有著不同的顏色,依照這些不同的顏色區分種類,每個token代表一種音色,比如鋼琴、小提琴等。視覺作曲家有趣的地方就是在演奏的過程中可以更換token來即時地改變每個顏色的音色。
圖2-5 Token與放置之圓形凹槽在視覺作曲家的盒身上有三個圓形凹槽,如上圖,分別用來擺放紅綠藍三種音色,將token放上後,不同的顏色便會依照token的種類發出不同的聲音。Token的另一個功能是用來改變音量,剛放上token時預設的音量為50%,若將token順時針旋轉,音量會變大直到變成100%,反之亦然。若將token拿下再放上,音量又會回復為預設的50%。
圖2-6 特徵點的決定開始時系統會自動辨識擺放凹槽,並從中央往外,以系統的角度取八個取樣點。在token放上凹槽之後,系統會從取樣點上取得顏色,並順時鐘排列這八個取樣點,使得開頭是兩個黑色,如圖2-6上方將會辨識成:黑-黑-藍-藍-紅-紅-綠-綠,來決定音色。這些取樣點稱之為「特徵點」。
當使用者轉動token時,系統保持特徵點位置不變,於是在轉到某個角度的時候,取樣點的顏色序列會改變,比如圖2-6下方,變成:綠-黑-黑-藍-藍-紅-紅-綠,於是系統知道此token經歷了順時針的轉動。四、自動定位
圖2-7 自動定位實體音樂盒本身只是個簡單的機械裝置,在CCD鏡頭下會將所擷取到的畫面輸入「視覺作曲家」系統。辨識時需要把擺放凹槽及紙帶的辨識區(黑白相間的開頭)置放在鏡頭下,系統會自動分析畫面的內容,解析出擺放凹槽的位置及紙帶的樣子。因此,只要符合規格,使用者也可以自由地建構喜歡的音樂盒樣式。
(Revision: 20 / 2011-08-28 14:26:22)





3. 效能參數 (Final Project Paper)
一、編譯資訊
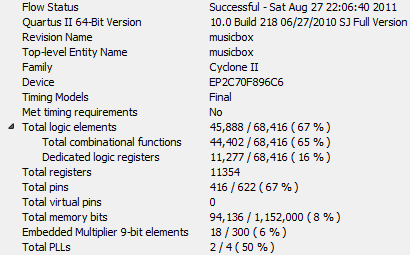
以下是視覺作曲家編譯的詳細資料:圖3-1 編譯資訊二、視覺辨識效能
視覺作曲家採硬體平行運算,在相機鏡頭的一次全屏掃描(稱為一幀影像)之後就可以完成所有需要的辨識演算。因此辨識速率是相機運作的速率,約66ms內可達成(採最高解析度),實際運作可以視為real time。三、音訊處理效能
音訊處理部分與audio的時脈有關,在兩個取樣點之間可以完成一整套運算。由於audio CODEC的運作頻率為44100Hz,而處理速率比44100Hz更高,所以實際運作可以視為real time。(Revision: 7 / 2011-08-30 16:19:45)
4. 設計架構 (Preliminary Paper)
一、系統架構:
圖4-1 系統架構圖子系統:
硬體控制部分:
CCD Capture:
把CCD Camera接收到的原始資料,轉換成RAW色彩格式傳出。Color Categorization:將收到的RAW色彩資料分類為黑、白、紅、綠及藍五種色彩。Audio CODEC:兼具錄放音功能,錄音的時候將Recorder的資料經由ADC轉換成數位資料輸入;播放的時候將來自Audio Processor的數位波形由DAC轉換為類比輸出。VGA Controller:把存放在SDRAM中的影像資料輸出到VGA Monitor,有助於觀察自動校正的情形。視覺辨識部分:
Token Processor:辨識擺放凹槽,解析出特徵點位置。將特徵點的顏色經過演算後算出token的種類以及token旋轉的角度,並將紅綠藍三種音色傳入Audio Processor,音量傳入Command Reader。
Keyboard Processor:辨識紙帶上的各列分界,將每一列中間所包含的顏色(即音高資訊)傳給Audio Processor,而指令列的資訊則傳給Command Reader。Command Reader:從Keyboard Processor取得指令資料,解析指令,考慮從Token Processor傳來的音量資訊後,輸出總音量大小與音域到Audio Processor。音訊處理部分:
Audio Processor:
根據Token Processor所指定的token音色、Keyboard Processor的音高及Command Reader所推算的音域從Memory中拿出每個成分的聲音,並依據Command Reader給定的紅綠藍音量比例相加後輸出到Audio Codec。錄音的時候辨識輸入的聲音頻率,演算出不同音高的聲音後存入Memory中。記憶體:
SDRAM:用來存放CCD Camera的視野。SRAM:用來存放使用者錄下的音色。FLASH:用來存放各種音色的聲音。外接硬體:
輸入端:CCD Camera:光學相機鏡頭,讀取辨識視野。Recorder:錄音器,錄製人聲用。輸出端:VGA Monitor:螢幕,輸出視野與自動校正訊息。Speaker:揚聲器,將音樂輸出。(Revision: 21 / 2011-08-30 17:01:51)
.png)
5. 設計方法 (Final Project Paper)
一、硬體控制部分:
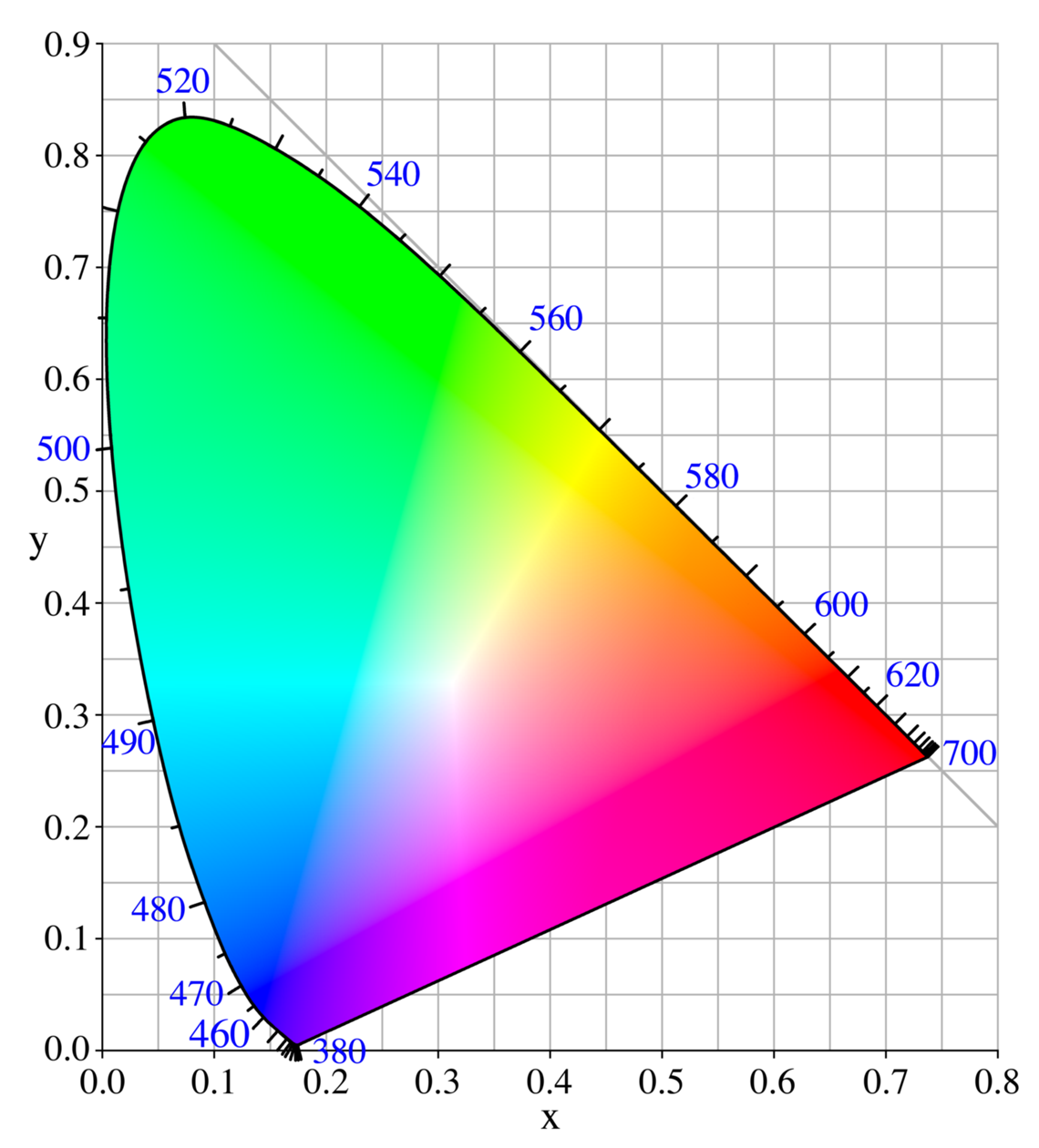
Color Categorization:視覺作曲家在運算之前的Color Categorization預處理運用到顏色分類的技術,此技術如下:圖5-1 CIE 1931色彩空間
資料來源:http://upload.wikimedia.org/wikipedia/commons/b/b0/CIExy1931.png?uselang=zh在CIE 1931色彩空間的定義之下,圖的右邊可以被辨識為紅色,上面是綠色,左下角是藍色。而不屬於這些的中間地帶,可以依照其亮度被辨識為黑色或是白色。視覺作曲家的核心演算來自於兩大部分:視覺辨識以及音訊處理。這兩個部分總共由四個有限狀態機組成,其概要如下。二、視覺辨識部分:
此部分是負責辨識攝影機的影像,讀取出使用者放的Token類型、以及紙帶的線段等等。考量到即時性以及記憶體數,在辨識上我們期望能夠做到Real Time,即攝影機每讀完一幀影像,就要刷新一次辨識結果。由於相機鏡頭讀進來的像素是由上至下,由左至右的序列,若每次都只處理當下的像素,而不將先前的像素存起來,能使用的演算法就會受到限制。以下的演算法都是專門針對這個特性所設計。Token Processor:1>Token槽定位程式啟動後,必須先抓到token槽的位置與大小,才能辨識token。硬體上我們將音樂盒的三個token槽分別塗上紅綠藍三種顏色,因此程式需要分別抓到畫面中最大的紅色、綠色、藍色圓形區域。以下敘述中假定我們要找的是紅色圓形區域。首先對畫面中每一行像素陣列(共1024行,每行為大小1280的陣列),我們都找出該陣列中最長的連續紅色線段。這裡的雜訊包括廣告顏料反光會形成小小的白色圓形,以及token槽最外圈的陰影產生的黑色雜點,為了處理這些雜訊,我們訂定每個紅色像素值2分,每個非紅色像素值-1分,並轉為找出總分數最高的子陣列(subarray),而這正是"maximum consecutive sequence problem",演算法僅需掃過一次陣列即可,恰好符合我們的需求。找出總分最高的連續陣列後,我們記住這線段的長度以及正中間的座標,姑且先稱之為「寬度」及「中間座標」。基於圓的對稱性,若畫面上有一個很大的紅色圓形,每一個經過這個紅色圓形的行的中間座標應相同。反之若現在有一個不對稱的紅色區塊,則它的中間座標就不會對齊。因此我們再找到一段最長的連續行,使得他們的中間座標都相同(允許一個小誤差範圍)。這時候,有兩個可以做為圓形直徑的數據,第一個是這段最長的連續行的長度,第二個是這段最長的連續行中最大的寬度。若這兩個值中都不會太小,並且兩者比例上差不多,則我們就判定我們找到了紅色圓形,否則就是定位錯誤,可能需要調整攝影機的畫面後再重新定位。若定位成功,我們就可以依據圓心以及圓半徑在圓面上取八個點,供之後的token辨識使用。2>Token辨識每個token會被分成四塊,其中三塊塗上紅綠藍三種顏色,第四塊塗上黑色。我們用黑色的位置來判斷Token旋轉的角度,來改變音量大小。而用剩餘的三個顏色來決定音色的種類。
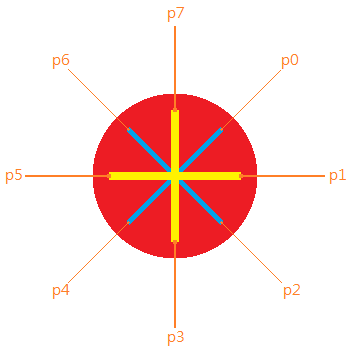
圖5-2 Token的特徵點
一旦已知token槽的中心點及半徑後,我們取出圓周上八個點的顏色,記為p0, p1, …,p7,如圖5-2所示。通常,只要從 p0, p2, p4, p6 這四點中找到黑色,譬如p4為黑色,那麼就將 {p6,p0,p2} 與音色表作比對,便能知道token代表的音色。至於 p1, p3, p5, p7 則是輔助用。token上四塊顏色的交界處顏色會很不穩定。當 p0, p2, p4, p6 無法從音色表中找到相符的音色,表示token上顏色的交界處可能恰好落在我們訂的 p0, p2, p4, p6 上,這時便須改用 p1, p3, p5, p7 做判斷。1>紙帶定位由於每次架硬體時,攝影機的高度、位置都會略有不同,當紙帶被插入後,程式必須先對紙帶上每個區間做定位,之後才能知道使用者繪製的線段是哪個音高。紙帶一共有25個區間,在紙帶最前段,我們將這25個區間黑白黑白地交錯塗色。一旦找到畫面中的一個呈現黑白交替紋路的辨識區,每個黑色或白色的區域分別就是那25個區間的位置了。除此之外,攝影機還會在黑白交替的紋路上訂出一條垂直的感應線。只有在繪製的線段觸碰到該線時才會發出聲音。紙帶辨識區域的雜訊較小,每一段顏色的長度也較短,因此token槽定位中的方法並不適用,反而是直接找夠長的連續黑色或白色效果比較好。第一步驟是對於每一行,都從頭掃過一次像素陣列,先以黑色為目標,找到一段足夠長的黑色區間,一旦找到後把計數器加一,改以白色為目標,往下找一段長度夠大的白色區間,找到後就再把計數器加一,把目標設回黑色……如此不斷重複下去。若掃到最後計數器大於等於26,就表示這行中有足夠多的黑白交替情形。與token槽定位相同,只要有一段連續的行,他們的計數器都大於等於26,並且這段連續的行的長度超過某個門檻值,那麼我們就相信我們要找的黑白交替紋路在這裡。這段連續行中的任何一行都可以作為感應線,實作上感應線是取最中間那行,以避免邊緣的雜訊干擾。以上步驟都只需要掃過一幀畫面就能夠完成。決定感應線後,我們再用第二幀畫面做第一步驟,不同的是我們這次將每個夠長的黑白區間端點保存起來,就可供紙帶辨識時使用。紙帶所辨識好的一些已知格式可以讓辨識結果更加準確。譬如在第一步驟中,我們可以改找一段長度界在某個上下界(如12~50像素)的連續黑/白色區間,如果長度小於下界則視為雜訊,長度大於上界,表示目前看到的區間應不屬於紙帶,則把計數器歸零。另外,紙帶上的黑色偶爾會被辨識成綠色或藍色,因此找黑色區間時可以讓綠色及藍色也被視為黑色。2>紙帶辨識要辨識出現在該發出的音非常容易而直觀,只要在感應線上,某一區間內有足夠多個像素的某種顏色,那麼該顏色所對應的音色就必須在該區間代表的音高發出聲音。為了避免使用者繪製或轉動紙帶時,不小心讓某條線段超出區間,跨到隔壁的音高上,我們在辨識時將每個區間的左右都內縮約三個像素,以減低區間邊緣造成的誤判。Command Reader:紙帶辨識完成之後,會將指令列的顏色資訊交給Command Reader處理。Command Reader是個有限狀態機,其狀態轉移圖如下:
圖5-3 Command Reader狀態圖
Token specification是起始狀態。當token被指定後,開始讀取對token的指令。這個過程如果出錯會進入error狀態,並回到token specification。過程中隨時可以按鍵進入reset狀態重設,或者是藉由發送指令重設。三、音訊處理部分:
Audio Processor:
Audio Processor可分成兩個部分,一部分處理樂器的樂聲,另一部分處理錄製的聲音(人聲),樂器的聲音存放在Flash Memory中,而錄製的聲音則存放在SRAM裡。1>樂聲處理
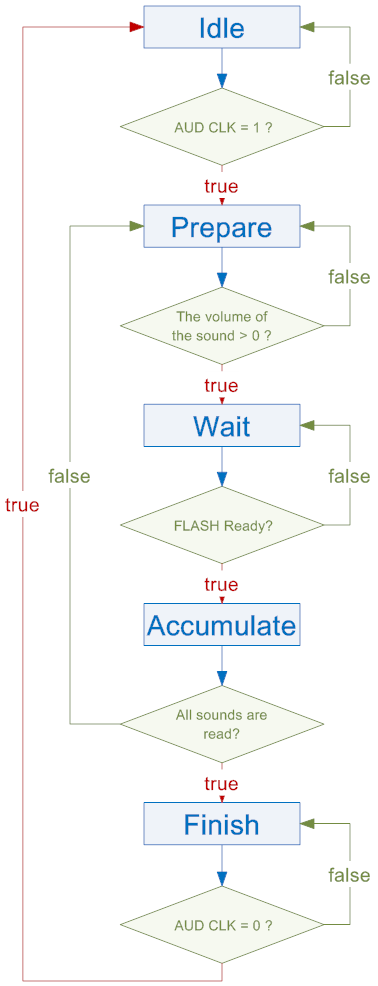
圖5-6 錄音處理狀態圖
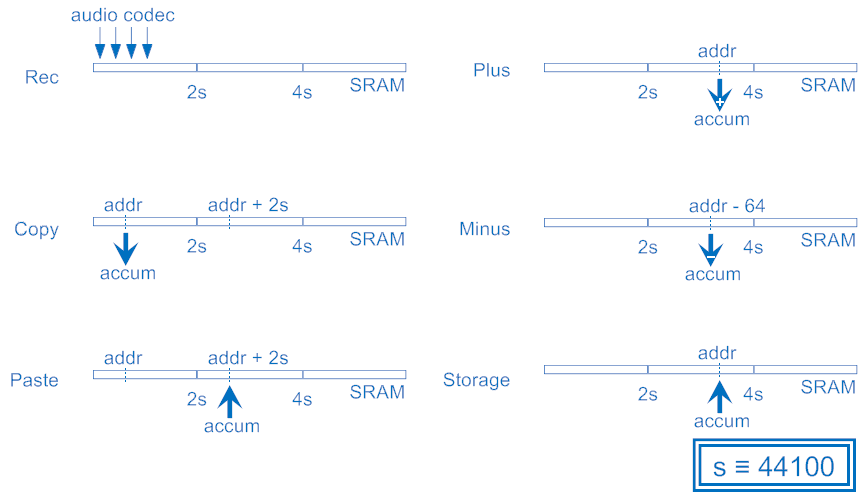
圖5-7 記憶體存取位置圖
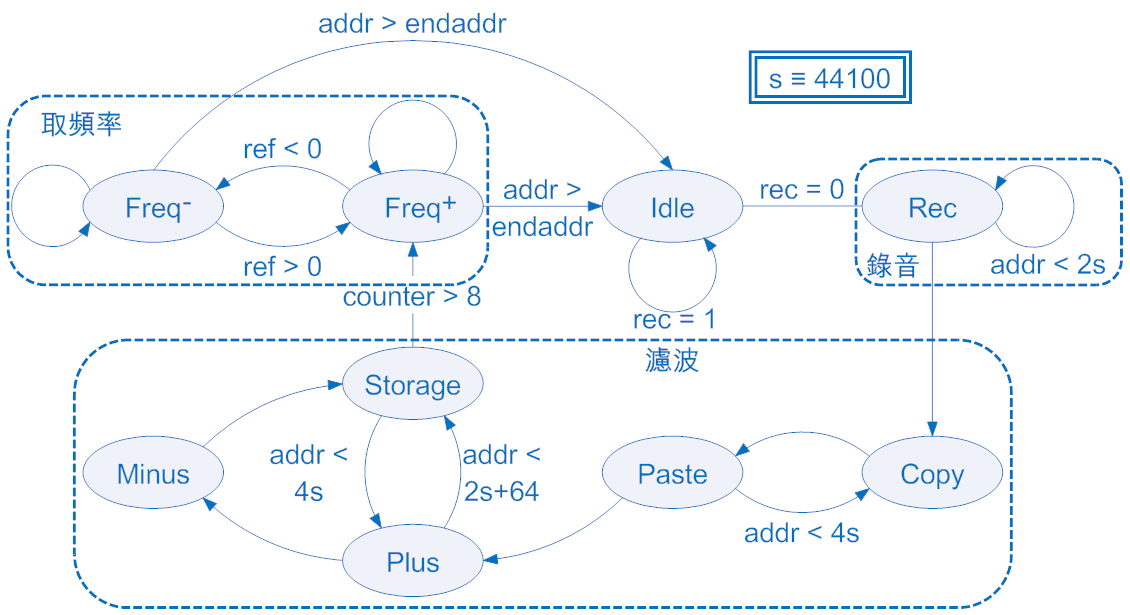
在錄音的時候可分成錄音、濾波和取頻率三個部分。在錄音的部分中會將Audio Codec進來的資料存入SRAM中0~2s的位置。濾波時會先將SRAM裡的資料複製到SRAM中2~4s的位置,接著讀取、累加並存入SRAM之中,若累加超過64筆資料就先扣掉64筆前的資料,再存入SRAM之中直到SRAM中2~4s裡所有的資料都累加完畢,這樣稱為一次的濾波,重複濾波數次後才進入取頻率的階段。要抓取聲音的頻率,除了複雜的演算如FFT以外,就是看聲音震幅通過零點的次數。但一般較為複雜的聲波在一個周期內可能會多通過零點好幾次,如圖5-8:
圖5-8 處理前聲波圖
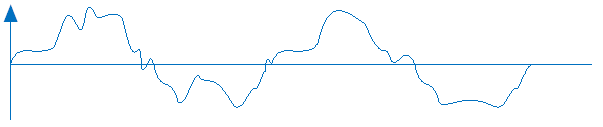
如果要避免這樣的情形,就必須將較為高頻的泛音濾掉,留下單純的基音。低通濾波可以用積分器來達成,不過這樣會將太多的直流成分累加,造成濾波後偏離原點。所以實作時只累加64筆資料,既達到低通濾波的效果,又不會累加太多的直流成份。經過濾波後的資料便可以用來作為原來資料每個周期的參照。
圖5-9 濾波後週期參照圖
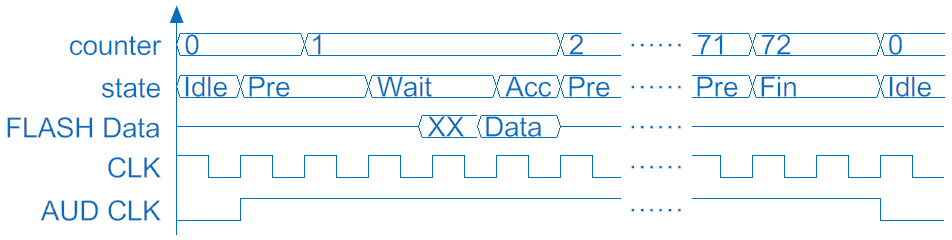
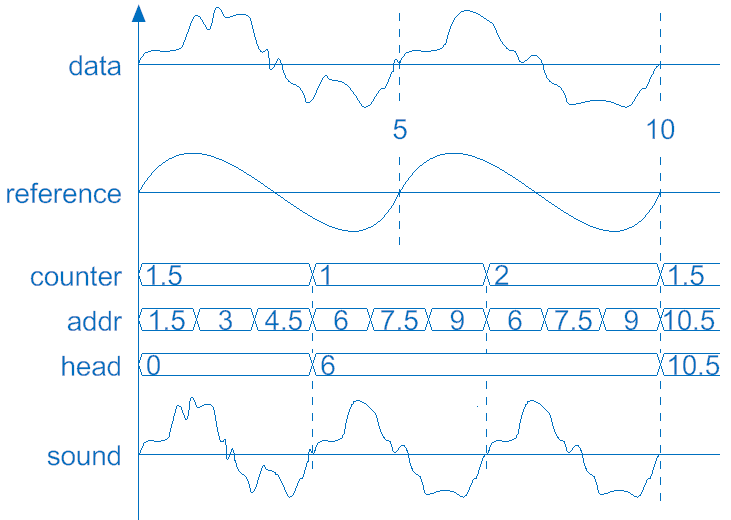
經過濾波後,只要計數存在SRAM位置2~4s的參照從負到正的次數就可以知道頻率了。在取頻率的階段若讀到參照為負,便會進入freq-的狀態,若在此狀態下讀到正的參照,頻率計數會加一並回到freq+的狀態。3>人聲處理在錄完聲音之後並處理完回到Idle狀態時便可以演奏人聲,人聲的不同音高也是由不同的播放速度完成。為了讓人聲和其他樂器同時演奏時能維持和諧,播放的速度會和錄音階段略有差異。除此之外,為了在合聲時每個聲音的時間可以相同,所以在播放過程中必須用演算法來補償因加速而被縮短的聲音。以下用1.5倍速作為例子說明此演算法的運作原理。在這個演算法中會有計數器counter來記錄所需補償的量;暫存器head來記錄這個週期的起始位置,初始值為0;暫存器addr(即address)來計算目前播放到的記憶體參照位址:
圖5-10 演算法範例時序圖
(Revision: 30 / 2011-08-30 17:07:04)
.png)
.png)
.png)
6. 設計特點 (Preliminary Paper)
一、直覺式創作介面
本產品的最大特點就是「直覺」,直覺地創作、直覺地使用。與傳統五線譜類似的格線安排,而又比五線譜的方式更直覺。具有樂理背景的人可以充分享受視覺作曲家的便利,而完全不會譜曲的人也能輕易上手,徜徉視覺作曲家奏出的樂音。閱讀並書寫傳統五線譜的譜記,需要了解各線與間隔的音高與音程關係,高中低音譜記號的意義與各種節拍的音符記號。透過紙帶與劃線的設計,使用者可以避開此一繁雜的過程。想要多長的音,就用多長的線條表示,或者透過轉動把手,自在地改變演奏速度。而以往困擾著演奏家的表情記號,也變成簡單的指令條設計。只要下指令,強、弱都不用再為了如何演奏而煩惱。二、自由組合--Token系統
除了極具親和力的紙帶演奏界面,另外一個重要的創新是token系統。在音樂盒上的音色token,可以讓音樂的演奏更加豐富。對於專業作曲者來說,同樣的旋律,到底要配合弦樂,還是管樂,有時不試一下很難決定。有了token系統,只要抽換不同的token,就可以讓同一段旋律用不同的樂器演奏。對於一般使用者來說,同樣的音樂,也可以透過抽換token來感受不同樂器搭配所帶來的樂趣。不僅如此,使用者也可以自行錄音,作為新的音色使用。除此之外,在不同的樂器之間,token也可以透過旋轉來調整各種樂器的音量大小。如果覺得背景伴奏太大聲了,那就輕輕地轉動token,讓聲音變小,簡單而直覺。三、自動定位,一指搞定
視覺作曲家的實體音樂盒,是可以自由設計的。只要包含了放置凹槽、紙帶讀取區便可以自行設計自己喜歡的音樂盒樣式。把放置凹槽與紙帶辨識區放在鏡頭下,簡單按下按鍵,視覺作曲家就會自動定位,非常簡單。四、CIE 1931與顏色辨識
視覺作曲家的重要功能之一就是畫面的辨識。利用CIE 1931色彩模型,我們大大地減低了色彩誤判的可能。即使在光線稍弱或者有其他光源的情形下,也能夠正確地辨識,降低雜訊干擾。五、純硬體的高效能平行運算
整套視覺作曲家系統乃利用純硬體來完成,和硬體的溝通更加直接更加的便利,而且達到高效率且完全即時的功效,讓使用者使用時感受前所未有的順暢。
六、人聲錄製,個性發聲
加入了有趣的人聲錄製功能,增添了視覺作曲家的趣味。自動校準音高讓錄製的人聲能和其他樂器和諧的搭配演奏,即時的等時補償讓播出的人聲不會因為不同的音高而長度不同。七、外接多媒體充分運用
要實現上述功能,系統需要使用外接的CCD Camera模組來擷取影像,以及DE2-70內建的Audio Codec輸出聲音,充分展現從視覺到聽覺的強大威力。八、高擴充性,製作你的特色音樂盒
視覺作曲家的核心演算法允許了包含實體音樂盒、token所代表的音色以及各種不同的指令效果有很高的自主性。只要記憶體允許,你可以任意地新增音色、改變token的意義以及自己製作有趣的實體音樂盒。
九、現在就使用「視覺作曲家」來實現生活的樂章!
要實作「視覺作曲家」,需要使用FPGA,如DE2-70,的邏輯單元來行影像辨識以及聲音演算,搭配外接的CCD Camera模組來擷取影像,以及一組揚聲器來播放輸出的聲音。此外,也可以使用錄音器來體驗人聲錄製的趣味。
(Revision: 12 / 2011-08-30 17:17:25)
7. 總結 (Final Project Paper)
視覺作曲家幾乎完整使用了Altera DE2-70所提供的多媒體功能:聲音、影像處理。從實作的過程我們發現CCD相機鏡頭的接線有長度限制,而且在qsf檔中藏有重要的硬體設置細節,這是先前在「數位電路實驗」課程中所沒有發現的。從三年級上學期開始就想組隊參加亞洲創新大賽,實驗室內大大的海報也是我們期末專題的重要藍色校正依據。修完數位電路實驗之後,融合了視覺辨識專長與音訊處理專長的兩組組成這次TW003的陣容,構想了全新的主題,投入這次創新大賽。這次的大賽讓人最開心的是團隊合作的感覺,每個人發揮個人專長完成了音樂盒的每一個小細節:簡伯宇擅長設計演算法,所有辨識的演算法都是由伯宇設計;曾士豪擅長與硬體溝通,與相機和VGA的溝通都是由士豪負責,除此之外音樂盒的外型的架構圖也是由士豪設計的;音樂盒的實作則要特別感謝士豪的室友,台大機械一哥群凱的大力相助;鄭為中則是擅長音樂的設計和聲音的處理,聲音處理器由為中一手包辦。每個人專心地處理自己的部分,安心地將自己的背後交給對方,這樣合作的感覺特別好。從無到有,從構想到實體,雖然在過程之中遇到了許許多多的問題,但在三人合力之下都迎刃而解,就像在RPG遊戲中不同職業的腳色合作的通過了一關又一關的考驗,迎接美妙的結局一般。當音樂盒第一次奏出「いつも何度でも」時,我們幾乎興奮到了極點。這段時間以來,我們一步一步地實現最初的構想。原本在紙上隨手畫的立方體,如今成為壓克力板組裝的透明音樂盒;一些好玩的功能,最初甚至還懷疑能否做到,但現在已經一一實現,有些甚至超越了一開始的想像。儘管除錯時很痛苦,寫硬體driver也很艱辛,但到後來益發地上手。對這次的作品的喜愛甚至超越這些困難,讓我們常常不知不覺就在實驗室待到凌晨。至今雖然大部分的功能都成熟了,但是又有更多更多的新點子不時迸出來,希望能夠有機會將它們完成,讓音樂盒更加地有趣。大學是廣闊湍急的江水,跳下去就被捲入名為現實的海中,只有用熱血搭起的橋樑,能夠把青春接到夢的彼岸。今年夏天,讓我們找回對創造的熱愛!(Revision: 7 / 2011-08-30 17:00:46)