Profile - TW030
TW030
聲控播放器

Project Paper - view as Preliminary(2010/07/21), Final(2010/11/01), Draft, Latest
1. 設計介紹 (Preliminary Paper)
你是否幻想過不用動手,用聲音就能切換歌曲呢?讓我們來實現你們的願望。本作品的主要設計目的就是能夠藉由麥克風輸入的聲音,來達成在音樂播放器上自動切換曲目的目的。
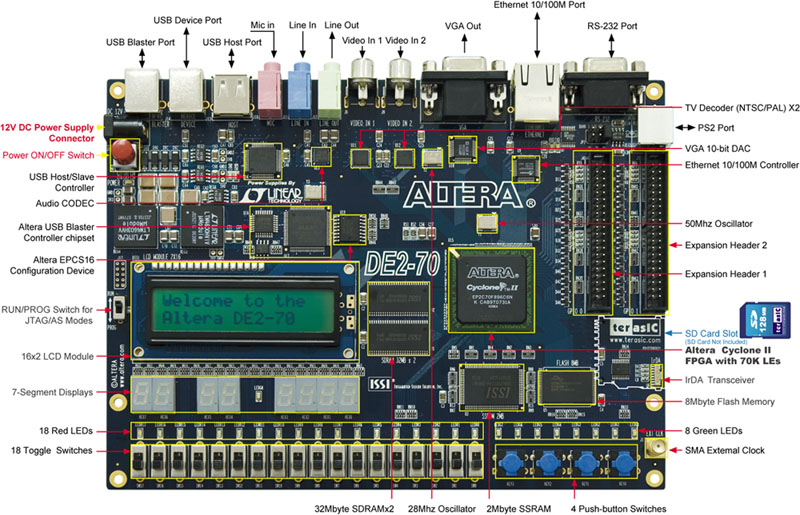
我們使用Altera公司發展的DE2-70板來實現功能,並且透過DE2上的Audio CODEC晶片及可程式化FPGA,製作出轉換分析的模組,達到辨識聲音指令的目的,產生出大略功能的作品,實現我們的夢想。首先在DE2-70上的SD Card Slot插入已準備好音樂的SD Card成一台音樂播放器,藉由Mic in插孔外接麥克風當作輸入端,透過麥克風輸入我們要下達的指令(ex.播放歌曲、切換曲目…等)並且存取至板子上的SDRAM。在Expansion Header插槽外接LCD Touch Panel上有選項可以觀看SD Card內的所有曲目,點及後也能使DE2-70 執行指定的播放功能。最後經由Line Out插孔外接喇叭將音樂播放器正在播放的曲目輸出。
圖1-1 DE2-70 Board(Revision: 4 / 2010-06-30 23:07:07)
2. 功能描述 (Final Project Paper)
1. 播放清單LCD Touch Panel:顯示指令讓使用者可以用觸控的方式操作。2. 聲控執行(1) 麥克風:接收聲音訊號,做為辨識來源。(2) 濾波器:處理雜訊,消除極端訊號,維持訊號比對較高之正確性。(3) 快速傅利葉轉換:利用離散之傅利葉轉換公式,進行聲音訊號的頻譜轉換,以進行比對。(4) 特徵值比對:以判別相異度之方法求出特徵值的相異度進行辨識,判斷是否為合法指令。(5) 執行指令: a.播放歌曲b.停止播放c.切換至下一首歌曲d.切換至上一首歌曲e.音量漸增f. 音量漸減3. 對指定歌曲執行與指令相應之動作,達到聲控播放器之目的。(Revision: 3 / 2010-09-17 12:46:20)
3. 效能參數 (Final Project Paper)
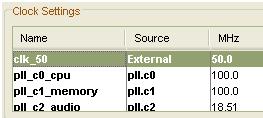
基本時脈是50MHz,透過一個pll元件到系統內可以增加一個100MHz的時脈,audio是友晶公司提供的IP,其時脈為18.51MHz。
圖 系統時脈
圖 Flow Summary(Draft / 2010-09-17 16:04:29)

4. 設計架構 (Preliminary Paper)
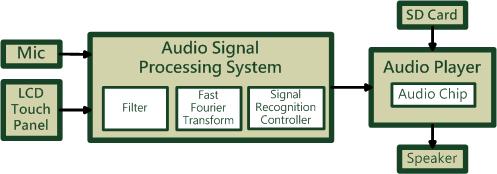
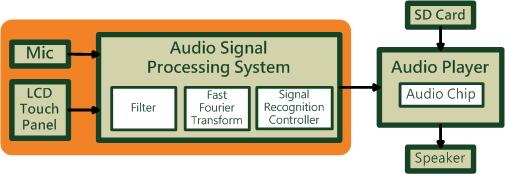
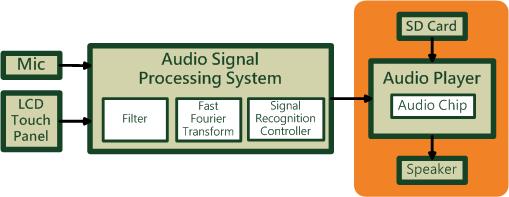
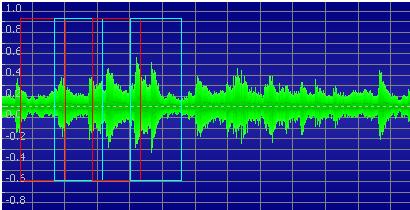
為了實現能夠用聲音來控制音樂播放的功能,我們的想法是用SD CARD去儲存音樂的wav檔,然後使用者在MIC的地方講一些樣本指令 (例如: NEXT或者是PLAY等等) 去控制,而這些指令接下來會傳到DE2板子裡去處理,把整個音檔截取成許多小的音框,然後根據短時距能量的大小來消除掉所處理的聲音一些細小音訊也就是去把一些比較小的雜訊去除掉。接下來是做一些運算以及傅利葉轉換成頻譜,使用傅利葉轉換的目的是要讓我們能夠更容易得去辨識,以及使用濾波器去把不重要的音頻部分消去,然後做了比對以及判斷以後,再使用倒頻譜的方式抓出基頻的位置。如此我們就能判斷使用者所輸入的指令(聲音)是否在我們規定的指令中,如果比對後成功的話,用DE2板子去對SD Card做功能,進而達成聲音播放器的夢想。圖4-1 架構外型圖4-2 整體架構圖FPGA chip:Nios II processor: 主要的處理器Audio port: 連接音源線的portFFT( Fast Fourier Transform ): 快速傅立葉轉換的模組Memory Controller: 記憶體控制裝置Cyclone II FPGA chip: 在板子上FPGA的晶片Control System:Mic: 外接的麥克風Output:Voice: 輸出的聲音LCD Touch Panel: 觸控面板圖4-3 總系統架構上圖為總系統架構圖,Mic為輸入端,聲音訊號送到Audio Signal Processing System裡做處理,經過一連串前置處理,Filter(濾波器)過濾,FFT (Fast Fourier Transform快速傅立葉轉換)轉成頻譜,最後透過Signal Recognition Controller,對訊號進行辨識處理,最後得到相應指令,傳到Audio Player執行指令。Audio Player能對外插的SD Card,做播放、下一首、音量增減等動作,是使用Audio Chip來實現的。當收到Audio Signal Processing System傳來的指令後,會先判斷該指令為何,在對指定元件做控制,完成指令由Speaker播出。直接觸碰LCD Touch Panel上的選單亦可播放指定歌曲。圖4-4 Audio Signal Processing System部分Audio Signal Processing System:對前一階段截取的音源部分,做過濾,轉換,辨識,最後傳出控制訊號到下一層。Input Microphone:由Mic輸入聲音訊號,做為下一步轉換辨識來源。Fiter(濾波器):用於雜訊過濾,利用去除短期波動,保留長期趨勢,提供訊號平滑形式。Fast Fourier Transform:快速傅立葉轉換模組,進行頻譜轉換的主要元件。Signal Recognition Controller:訊號辨識的模組,硬體軟體整合加速的主要元件。圖4-5 Audio Player部分Audio Player:執行前階段輸入的指令,由喇叭和觸控板進行輸出。SD Card:內存數首聲音檔,為.wav格式。Audio Chip:前一階段傳送來的控制訊號,做指定的動作,播放SD卡中的wav檔。(例如: 播放.下一首…等)LCD Tocuch Panal:輸入訊號的波形圖,顯示在觸控板上。Speaker:經過Audio Chip裡的運作,播放出聲音。圖4-6 波型圖範例
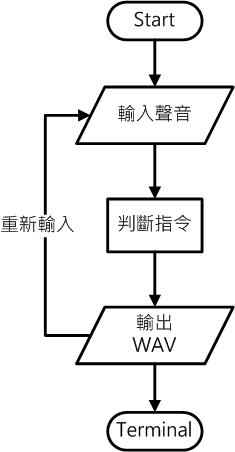
圖4-7 大略流程圖
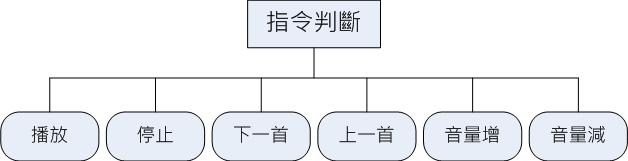
Step1 : 開啟Step2 : 使用者輸入指令Step3 : 判斷何種指令Step4 : 執行指令並輸出wav.Step5 : 結束執行的指令如下:圖4-8 指令判斷圖圖4-9 聲音處理細部流程
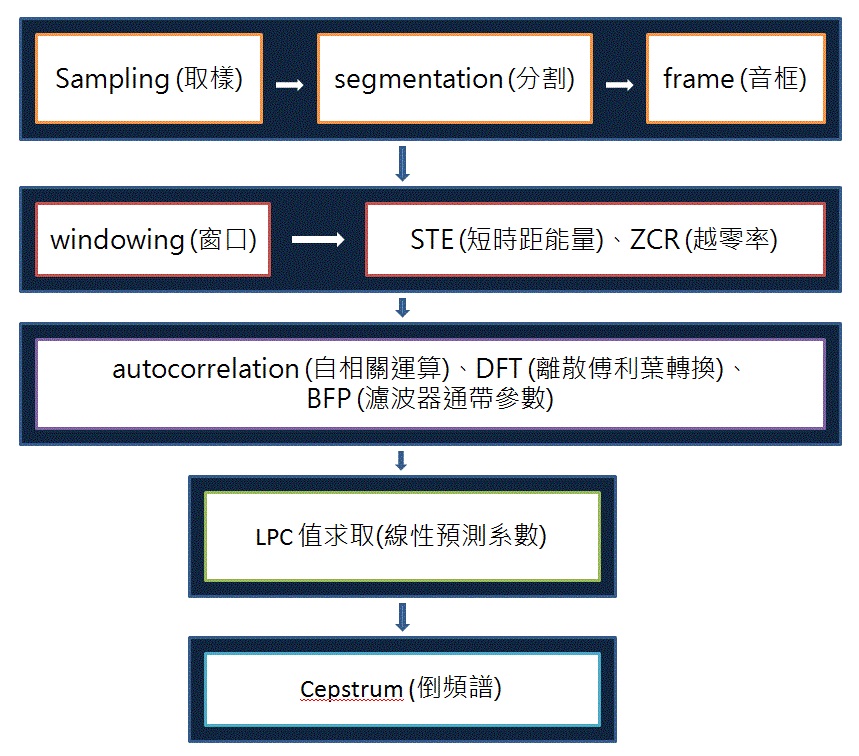
Sampling (取樣)錄製聲音,將聲音數位化之後存進記憶體裡備用。segmentation (分割)將語音訊號分割成數小段,以便處理應用。frame (音框)求特徵參數前,需先把語音訊號分成一小段的序列,而且音框與音框間可以有部分重複。windowing (窗口)為了讓各個音框在頻譜上的能量更集中,我們將每個音框內的取樣值再乘上一個漢明視窗。STE (短時距能量)短時距能量(STE)是代表音量的高低,我們可以根據短時距能量的大小來刪掉所處理的聲音一些細小音訊。ZCR (過零率)當越零點的值越多,就表示所處理的聲音頻率越高,反之則表示所處理的聲音為低頻。DFT (離散傅利葉轉換)把時間軸上的訊號轉換到頻譜上來處理,高頻訊號只在高頻部分有較大的能量值,低頻訊號在低頻的能量較大,這些在頻譜上的能量值便可稱為一種特徵值。BFP (濾波器通帶參數)衰減到極低水平的濾波器。指能通過某一頻率範圍內的頻率分量、但將其他範圍的頻率分量LPC 值求取(線性預測系數)線性預測的基本原理,是假設目前的聲音取樣值,可由在前面的P個取樣值以線性組合來預測。因為大部分的語音訊號都具有週期性Cepstrum (倒頻譜)在頻域上的音高追蹤的方法,只要使用 high-pass liftering,就可以把在 low quefrency 部分拿掉,突顯高點,就可以抓出基頻的位置。
(Revision: 6 / 2010-09-17 15:57:52)
.jpg)
5. 設計方法 (Final Project Paper)
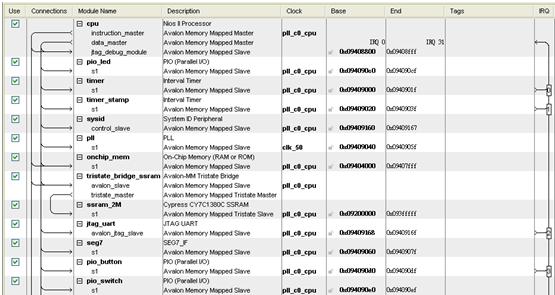
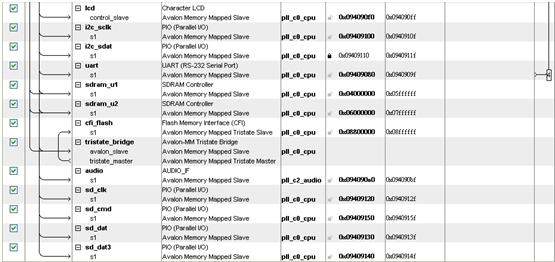
SOPC建置如下:
圖 Altera SOPC builder 1
圖 Altera SOPC builder 2
圖 SOPC 製作出的module 1
圖 SOPC 製作出的module 2
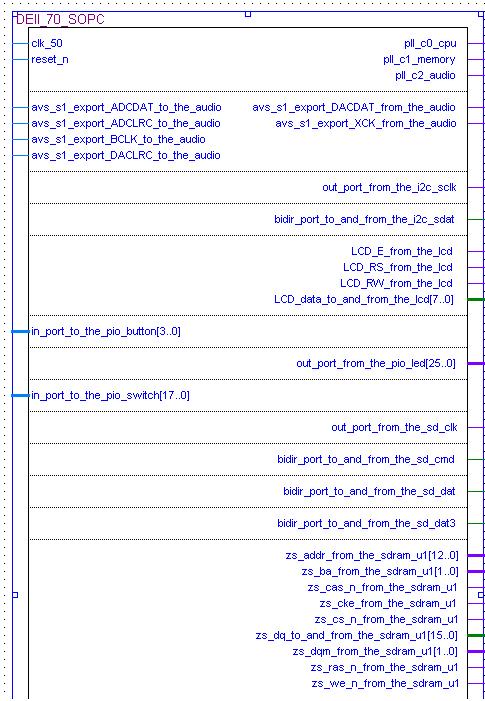
是直接經由SOPC Builder介面選取,包含On-ChipMem,SSRAM,SDRAM等等。友晶公司提供的IP,SDcard的部分,是透過三個PIO,加一個PIO的clk,即可達成SD卡的讀取,其他是軟體部分。特徵值截取:將聲音資訊數位化,再將這些資料轉換成能代表這段聲音的特徵值,是做語音辨識的必要步驟,而在語音辨識部分常用的是「梅爾倒頻譜係數」(Mel-scale Frequency Cepstral Coefficients,簡稱MFCC)。第一步驟是先將截取的點做"預強調"(Pre-emphasis),是讓來源資料通過一個高通濾波器,目的是為了消除發聲過程中聲帶和嘴唇的效應,來補償語音信號受到發音系統所壓抑的高頻部分。若以時域的運算式來表示,預強調後的訊號 s2(n) 為s2(n) = s(n) - a*s(n-1)首先,將由麥克風錄製的音訊做"音框化"(Frame blocking),也就是將數個取樣點及合成一個音框,音框與音框之間,須有一些重疊部分,目的是避免兩音框相差過大。
圖 音框示意圖
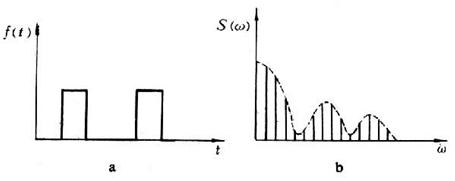
在把每個音框乘上"漢明窗"(Hamming window),目的是增加音框兩側連續性。W(n, a) = (1 - a) - a cos(2pn/(N-1)),0≦n≦N-1緊接著需要做的是"快速傅利葉轉換"(Fast Fourier Transform, or FFT),這個動作是將音訊由訊號在"時域"(Time domain)轉換成"頻域"(Frequency domain),原因是前者的變化通常不容易看出訊號的特性,而由能量分佈來觀察,較能代表不同音訊的特性。
圖 時域與頻域示意圖
"梅爾濾波器"(MelFilters):將前一步得出的頻譜能量乘以一組數個三角帶通濾波器,求得每一個濾波器輸出的對數能量(Log Energy)。其目的在於,不讓結果因為輸入語音的音調不同而有所影響。這些三角帶通濾波器在「梅爾頻率」(Mel Frequency)上是平均分佈的。梅爾頻率代表一般人耳對於頻率的感受度,以下是梅爾頻率和一般頻率 f 的關係式:
mel(f)=2595*log10(1+f/700)"離散餘弦轉換"(Discrete cosine transform, or DCT)將上述的對數能量帶入離散餘弦轉換,求出 L 階的 Mel- scale Cepstrum 參數,這裡 L 通常取 12。離散餘弦轉換公式如下:Cm=Sk=1Ncos[m*(k-0.5)*p/N]*Ek, m=1,2, ..., L採用 DCT 轉換是期望能轉回類似 Time Domain 的情況來看。"對數能量"(Log energy):音框的音量,也是語音的重要特徵,使得每一個音框基本的語音特徵有 13 維(包含了 1 個對數能量和 12 個倒頻譜參數)。"差量倒頻譜參數"(Delta cepstrum):意義為倒頻譜參數相對於時間的斜率,也就是代表倒頻譜參數在時間上的動態變化,公式如下:△Cm(t) = [St=-MMCm(t+t)t] / [St=-MMt2]加上差量與差差量運算會產生 39 維的特徵向量。
在把每個音框乘上"漢明窗"(Hamming window),目的是增加音框兩側連續性。
W(n, a) = (1 - a) - a cos(2pn/(N-1)),0≦n≦N-1緊接著需要做的是"快速傅利葉轉換"(Fast Fourier Transform, or FFT),這個動作是將音訊由訊號在"時域"(Time domain)轉換成"頻域"(Frequency domain),原因是前者的變化通常不容易看出訊號的特性,而由能量分佈來觀察,較能代表不同音訊的特性。
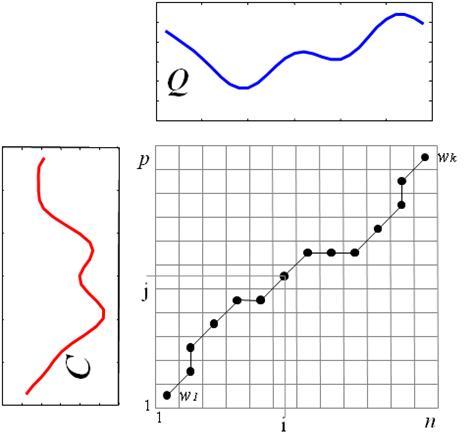
辨識:辨識部分,由於不能保證測試的聲音資訊與存在SD卡內的範例長度會一致,所以我們先使用"Dynamic Time Warping"(「動態時間扭曲」或是「動態時間校正」),先規畫範例與測試檔之間的對應關係。
圖 DTW圖示1
圖 DTW圖示2
測試檔與每個範例做DTW進而算出兩個向量之間的最短距離。對於兩個 n 維空間中的向量 x 和 y,它們之間的距離可以定義為兩點之間的直線距離,稱為歐基里得距離(Euclidean Distance)dist(x, y) = |x - y|2最近者即為所求。(Revision: 7 / 2010-09-17 18:13:44)

6. 設計特點 (Preliminary Paper)
硬體方面:1. 使用 SOPC builder,選取元件(板子上和板子以外),做連結與整合。2. 使用 FFT 模組,節省使用軟體轉換的時間。3. 進行 Import assignment4. 將完成的開發 download 至 DE2-70 板子上進行功能驗證。軟體方面:1. 使用 C語言對聲音訊號實作辨識,執行指令動作。2. 進行硬體描述語言 Verilog 合成。3. 使用 C2H Compiler 將演算法中較花時間的部分抽出,做成硬體模組達到加速效果。
(Revision: 2 / 2010-06-30 17:41:27)
7. 總結 (Final Project Paper)
在這次的比賽我們學到了很多東西,因為學校的課程只有簡單的使用DE2的板子去寫一些簡單的code去跑,所以可能在學校中沒有辦法學的這麼的深入,但這次的比賽我中我們學到如何去使用c就可以直接跟板子連接、學到硬體與軟體的真正差別在於哪個部分、學會如何寫c的code(學校是學java)等等。
不過在這之中我們也遇到了許許多多的困難,簡單的舉幾個例子:
1. 在板子上我們當初使用c的linklist演算法,但是卻無法正確的讀到值,不知道是我們code寫錯還是哪裡有問題。2. C2H的製作沒有想像中的簡單,讓我們花費許多心思。3. SOPC的建制繁雜,研究了許多範例才順利建造出來。當初因為這些問題我們也想過放棄,但是還是硬撐了下來,從原本的特徵值一直沒有東西,改到了正確的特徵值!從原本完全不會寫c的code寫到現在已經看得懂大部分的code,許許多多的改變都是經由這次的比賽!也因此我們很感謝這次的比賽。而最後我們列出幾項應該要改善的部分:1. 在辨識的部分可能沒有辦法順利的達到即時就可以完成。2. 在建置我們要運算的陣列時會花上較多的時間,希望接下來可以用C2H的功能去改善。3. 在辨識的準確度希望能夠更加提高。4. 未能使用所有板子上所有的硬體資源。5. 軟體程式的演算法並非為最有效率的方法。聲音辨識這個議題的是現今辨識的一大議題,不管是在手機上能夠辨識聽到的是何種歌曲的小程式,或者是在電影中看到講甚麼就能控制所有傢俱的功能,這些都跟聲音辨識息息相關,經由這些理由我們才會挑此題目,也希望由這次的學習讓我們了解聲音辨識並非只是科幻,我們自己就可以做出來,最後再次感謝此比賽讓我們能夠實現童年的夢想。(Draft / 2010-09-17 16:39:50)